
La comunidad de IA ha estado entusiasmada con el último modelo de lenguaje grande (LLM) de OpenAI, GPT-4 , que ha demostrado ser un cambio de juego en el campo de la comprensión del lenguaje natural. A diferencia de sus predecesores, la naturaleza multimodal de GPT-4 le permite realizar tareas complejas de visión y lenguaje, como generar descripciones detalladas de imágenes, desarrollar sitios web utilizando instrucciones de texto escritas a mano e incluso crear videojuegos y extensiones de Chrome.
Las razones detrás del rendimiento excepcional de GPT-4 no se entienden completamente, pero algunos expertos creen que se debe al uso de un modelo de lenguaje grande más avanzado.
Para explorar esta hipótesis, un equipo de Ph.D. estudiantes de la Universidad de Ciencia y Tecnología King Abdullah, Arabia Saudita, ha desarrollado MiniGPT-4, un modelo de código abierto que realiza tareas complejas de visión y lenguaje al igual que GPT-4. MiniGPT-4 utiliza un LLM avanzado llamado Vicuña como decodificador de idioma, que se basa en LLaMA y logra el 90 % de la calidad de ChatGPT según la evaluación de GPT-4.
Además, MiniGPT-4 utiliza el componente de visión previamente entrenado de BLIP-2 y ha agregado una única capa de proyección para alinear las características visuales codificadas con el modelo de lenguaje Vicuña.
No te dejes engañar por el nombre
MiniGPT-4 ha mostrado excelentes resultados en la identificación de problemas a partir de la entrada de imágenes, como proporcionar una solución basada en la entrada de imágenes de una planta enferma proporcionada por un usuario con un mensaje que pregunta qué le pasaba a la planta.
Incluso ha demostrado la capacidad de generar recetas detalladas al observar fotos de comida deliciosa, escribir anuncios de productos y crear canciones de rap inspiradas en imágenes. Sin embargo, el equipo mencionó que entrenar MiniGPT-4 usando pares de imagen y texto sin procesar de conjuntos de datos públicos puede resultar en frases repetidas u oraciones fragmentadas. Para superar esta limitación, MiniGPT-4 debe entrenarse con un conjunto de datos bien alineado y de alta calidad.
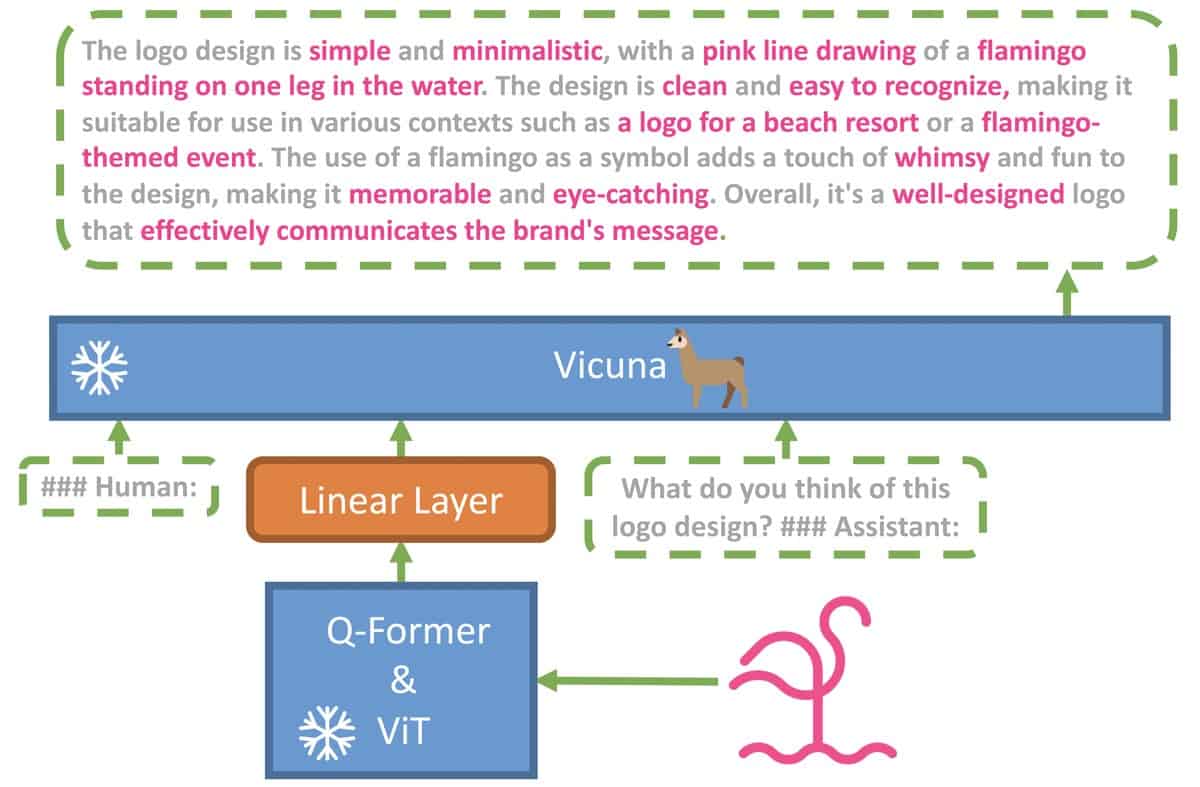 MiniGPT-4 funciona con Vicuña - Imagen cortesía de MiniGPT-4
MiniGPT-4 funciona con Vicuña - Imagen cortesía de MiniGPT-4
Uno de los aspectos más prometedores de MiniGPT-4 es su alta eficiencia computacional, que requiere solo aproximadamente 5 millones de pares de imágenes y texto alineados para entrenar una capa de proyección. Además, MiniGPT-4 solo necesita ser entrenado durante aproximadamente 10 horas en 4 GPU A100, lo que lo convierte en un modelo de IA altamente eficiente y accesible.
El código, el modelo preentrenado y el conjunto de datos recopilados están disponibles, lo que convierte a MiniGPT-4 en una valiosa adición a la comunidad de IA de código abierto. Puede probar MiniGPT-4 aquí .